3D FlowMatch Actor

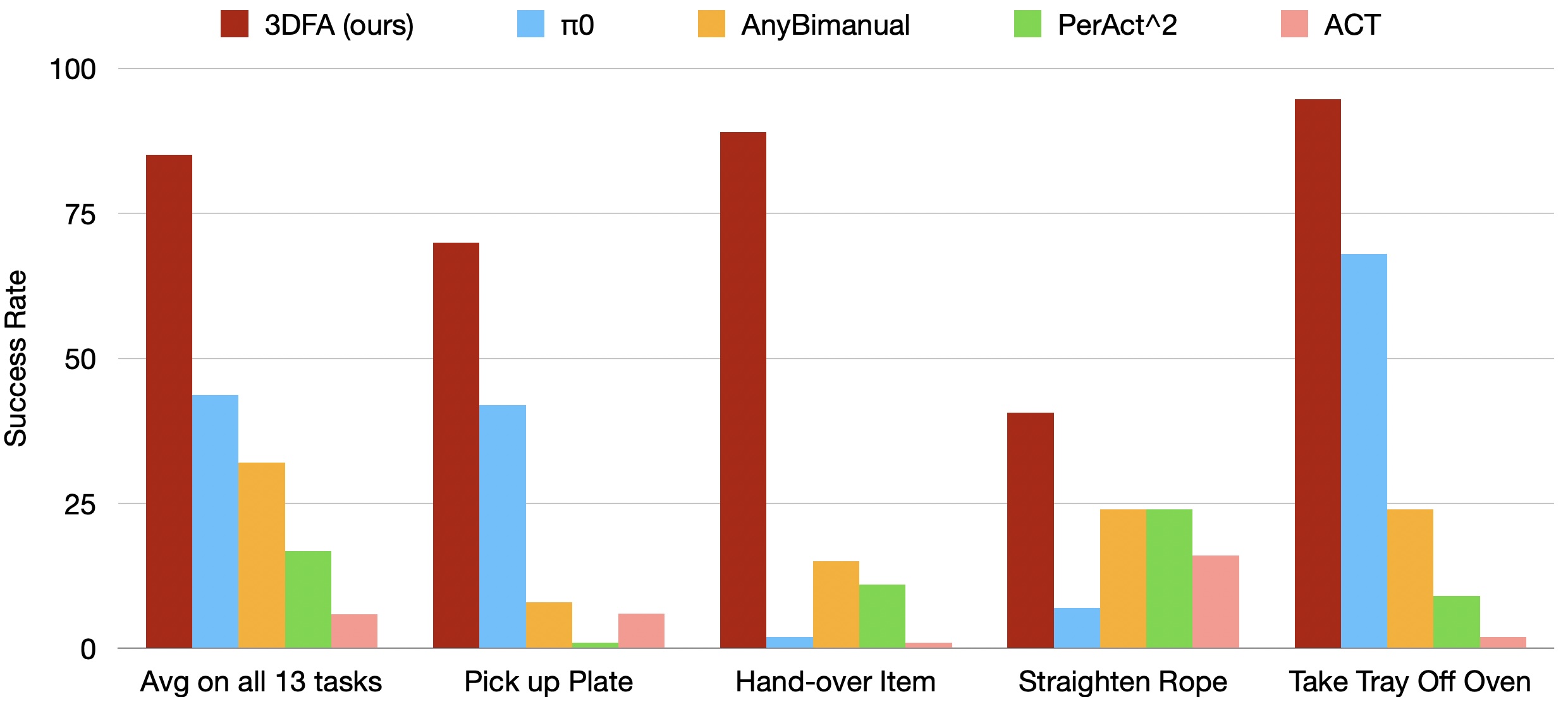
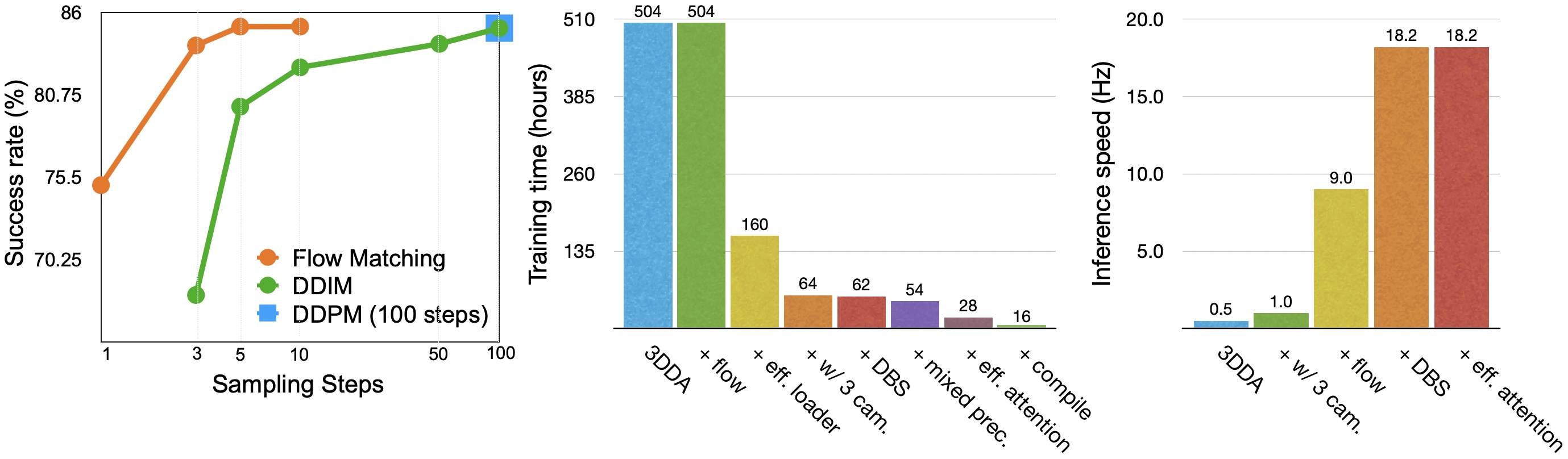
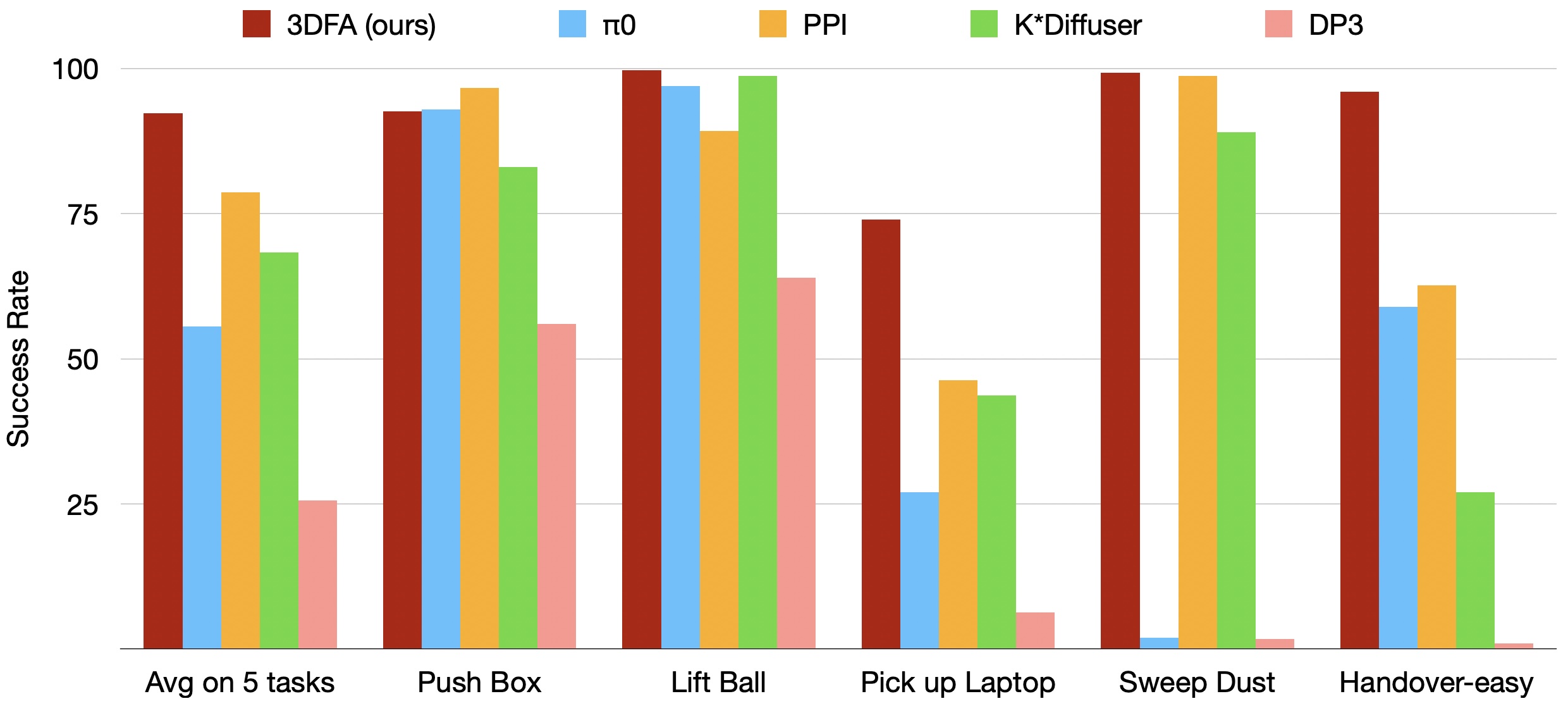
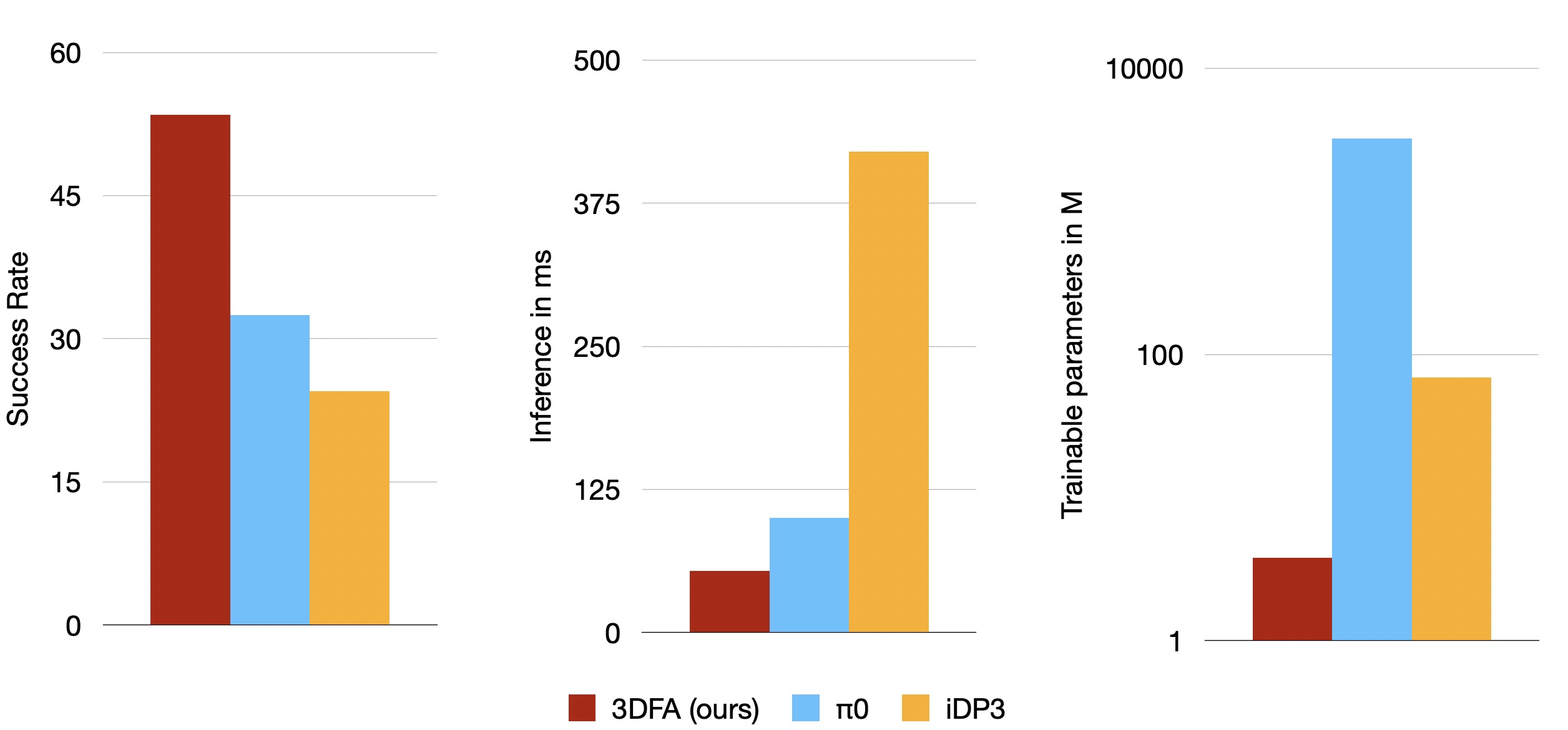
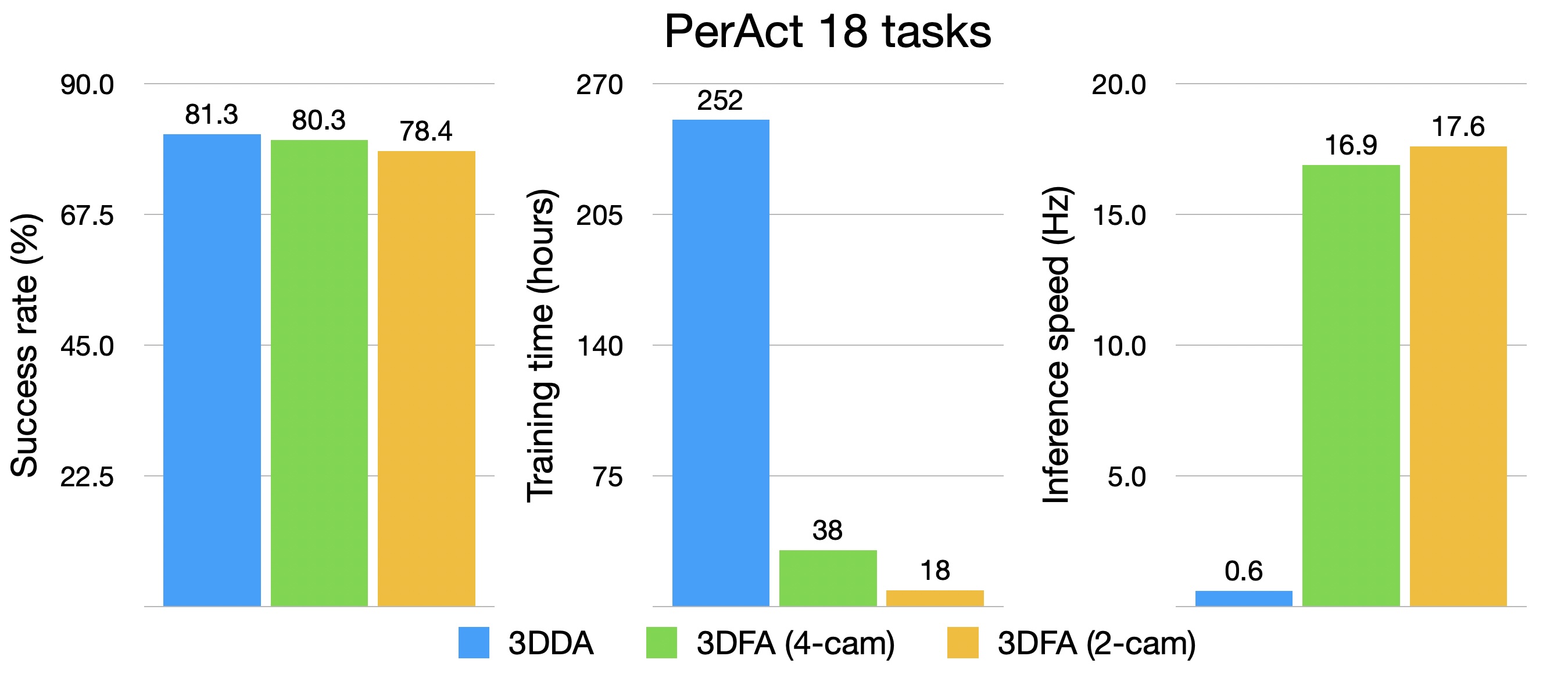
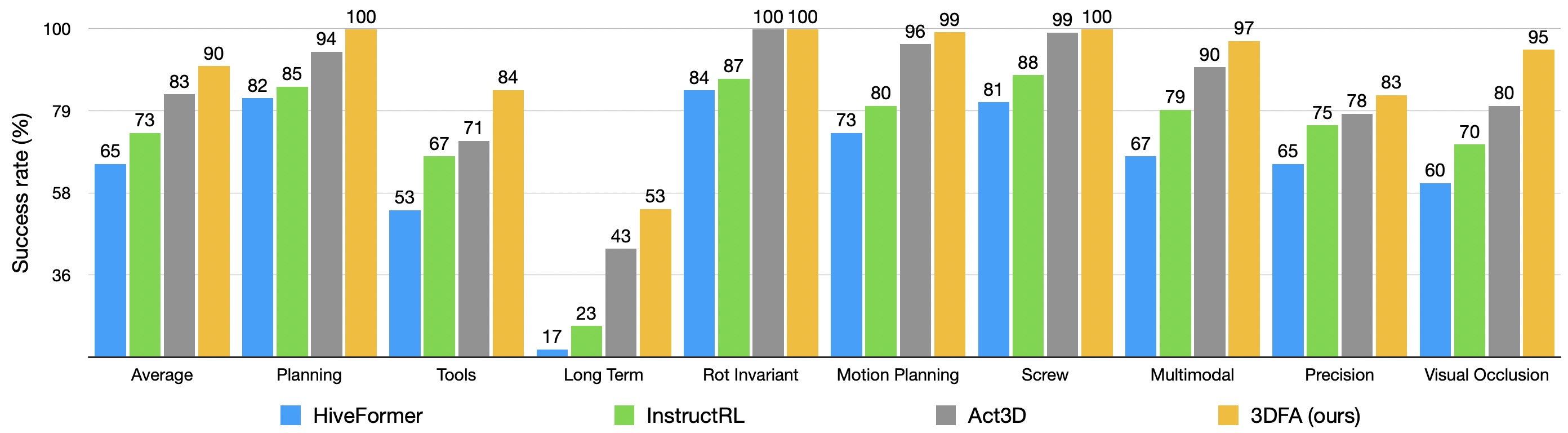
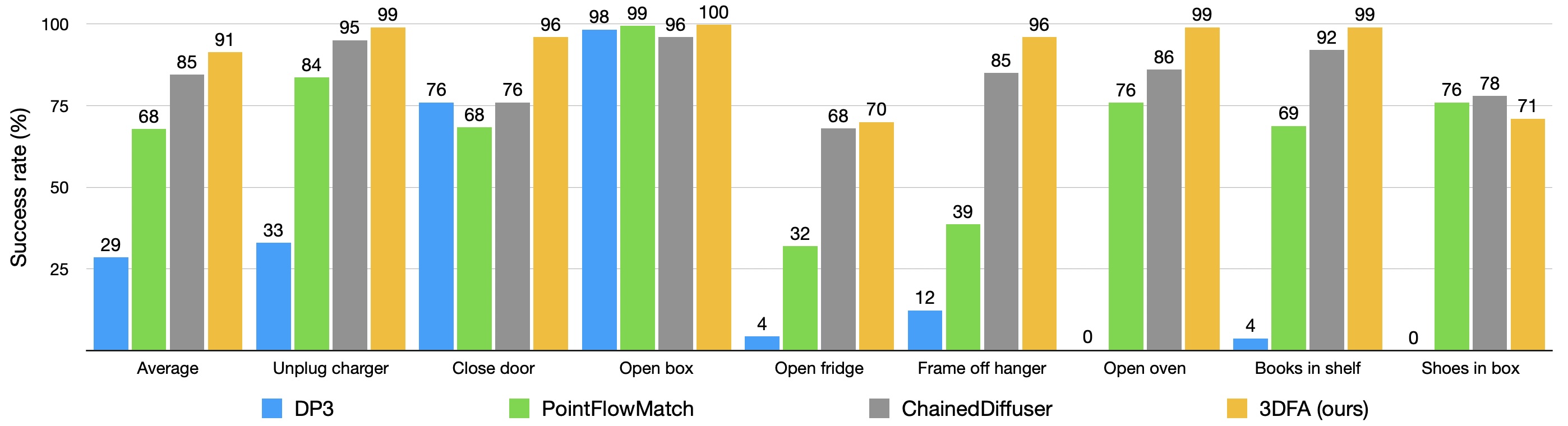
We present 3D FlowMatch Actor (3DFA), a 3D policy architecture for robot manipulation that combines flow matching for trajectory prediction with 3D pretrained visual scene representations for learning from demonstration. 3DFA leverages 3D relative attention between action and visual tokens during action denoising, building on prior work in 3D diffusion-based single-arm policy learning. Through a combination of flow matching and targeted system-level and architectural optimizations, 3DFA achieves over 30x faster training and inference than previous 3D diffusion-based policies, without sacrificing performance. On the bimanual PerAct2 benchmark, it establishes a new state of the art, outperforming the next-best method by an absolute margin of 41.4%. In extensive real-world evaluations, it surpasses strong baselines with up to 1000x more parameters and significantly more pretraining. In unimanual settings, it sets a new state of the art on 74 RLBench tasks by directly predicting dense end-effector trajectories, eliminating the need for motion planning. Comprehensive ablation studies underscore the importance of our design choices for both policy effectiveness and efficiency.